| Model Name |
Relevance |
Answerability |
Diversity |
Pedestrian Centric |
Vehicle Centric |
Specific (Grounded) |
Generic |
| BU | Atr | ER | RR | CI |
BU | Atr | ER | RR | CI |
BU | Atr | ER | RR | CI |
BU | Atr | ER | RR | CI |
BU | Atr | ER | RR | CI |
BU | Atr | ER | RR | CI |
BU | Atr | ER | RR | CI |
| Gemini 2.5 Pro |
92 | 84 | 82 | 86 | 80 |
90 | 80 | 80 | 84 | 82 |
64 | 62 | 66 | 64 | 60 |
35 | 30 | 45 | 40 | 50 |
55 | 60 | 50 | 55 | 45 |
70 | 80 | 65 | 60 | 55 |
30 | 20 | 35 | 40 | 45 |
| Qwen3 Max |
82 | 84 | 84 | 85 | 85 |
92 | 88 | 88 | 88 | 88 |
50 | 50 | 48 | 50 | 50 |
33 | 41 | 49 | 46 | 43 |
67 | 59 | 51 | 54 | 57 |
38 | 45 | 56 | 57 | 49 |
62 | 55 | 44 | 43 | 51 |
| Gemini Flash |
78 | 84 | 82 | 84 | 80 |
77 | 81 | 80 | 83 | 82 |
64 | 43 | 50 | 47 | 41 |
36 | 43 | 50 | 47 | 41 |
64 | 57 | 50 | 53 | 59 |
39 | 45 | 58 | 56 | 50 |
61 | 55 | 42 | 44 | 51 |
| Qwen3-VL-235B |
70 | 76 | 79 | 81 | 74 |
76 | 80 | 80 | 82 | 77 |
56 | 59 | 62 | 63 | 58 |
31 | 44 | 49 | 46 | 42 |
69 | 48 | 55 | 58 | 50 |
42 | 48 | 55 | 58 | 50 |
58 | 52 | 45 | 42 | 50 |
| Gemini 2.5 Flash |
74 | 70 | 72 | 68 | 72 |
86 | 85 | 84 | 83 | 85 |
34 | 34 | 34 | 33 | 33 |
38 | 44 | 49 | 46 | 42 |
62 | 56 | 51 | 54 | 58 |
41 | 47 | 55 | 57 | 46 |
59 | 53 | 45 | 43 | 54 |
| Qwen3-VL-30B |
72 | 78 | 77 | 79 | 74 |
76 | 80 | 79 | 81 | 78 |
47 | 48 | 50 | 50 | 50 |
34 | 43 | 51 | 48 | 45 |
66 | 57 | 49 | 52 | 55 |
39 | 46 | 56 | 58 | 50 |
61 | 54 | 44 | 42 | 50 |
| GPT-5 |
71 | 73 | 75 | 77 | 72 |
77 | 79 | 80 | 82 | 78 |
53 | 55 | 57 | 59 | 55 |
34 | 42 | 47 | 46 | 43 |
66 | 58 | 53 | 54 | 57 |
38 | 44 | 56 | 58 | 48 |
62 | 58 | 44 | 42 | 52 |
| GPT-4o |
39 | 41 | 38 | 34 | 35 |
52 | 58 | 53 | 60 | 51 |
7 | 10 | 8 | 11 | 9 |
19 | 13 | 45 | 38 | 50 |
51 | 85 | 53 | 61 | 40 |
0 | 1 | 17 | 56 | 77 |
100 | 98 | 82 | 43 | 23 |
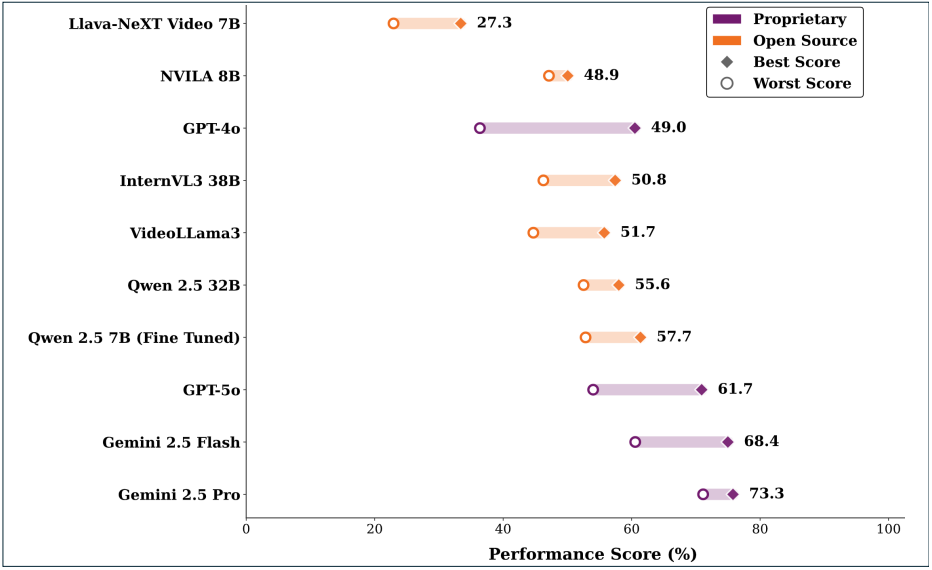
The VideoQGen Benchmark. Evaluating multimodal models across reasoning types, including basic understanding (BU), attribution (Atr), event reasoning (ER), reverse reasoning (RR), and counterfactual inference (CI). Gemini 2.5 Pro leads overall across relevance, answerability, and diversity dimensions, showing strong consistency across all reasoning categories.
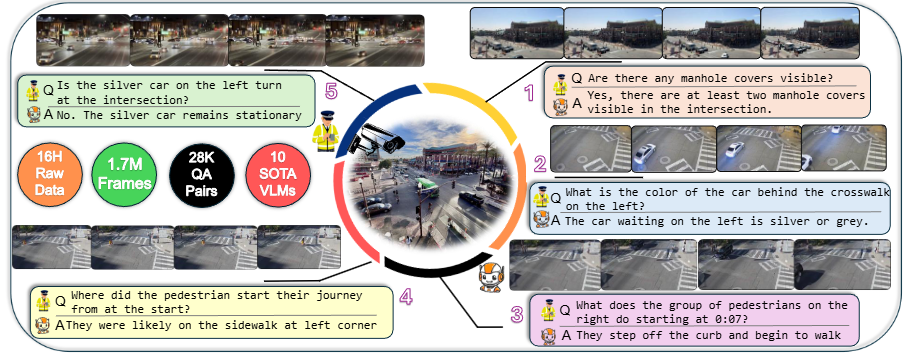
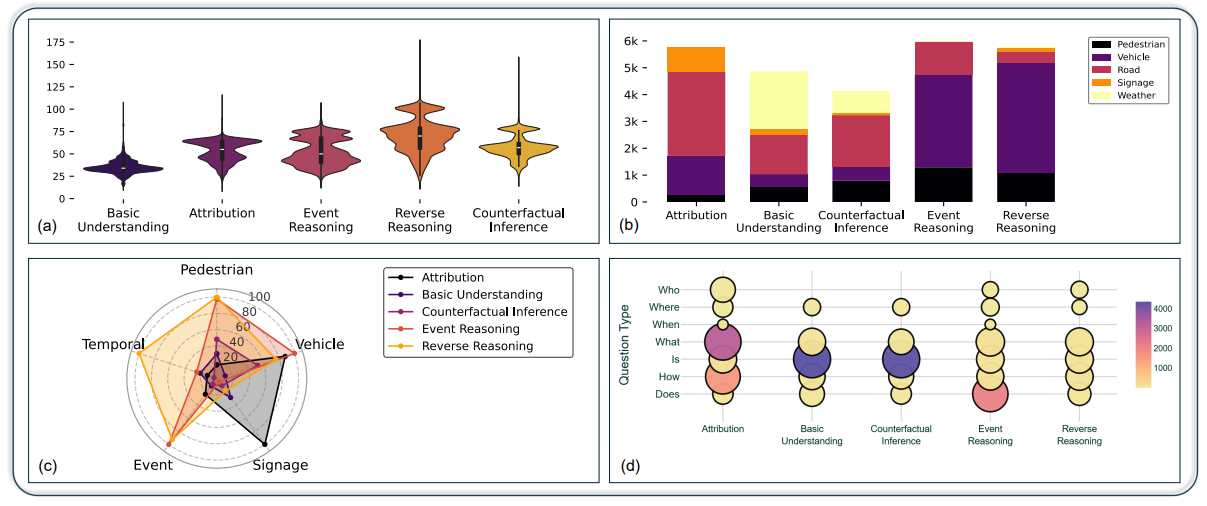
Overview of the UD-VideoQA dataset, which comprises 28,800 question-answer pairs across various
reasoning categories. A higher concentration appears in counting, attribute recognition, and event
reasoning, followed by counterfactual inference and reverse reasoning (3a). Figures 3(b)-(d) illustrate
the dataset's emphasis on vehicular-related questions, the dominance of attribution and event reasoning
categories, and the distribution of question types ("what," "where," and "how"). This structured approach
supports the analysis of complex, multi-event traffic scenarios, requiring robust spatio-temporal
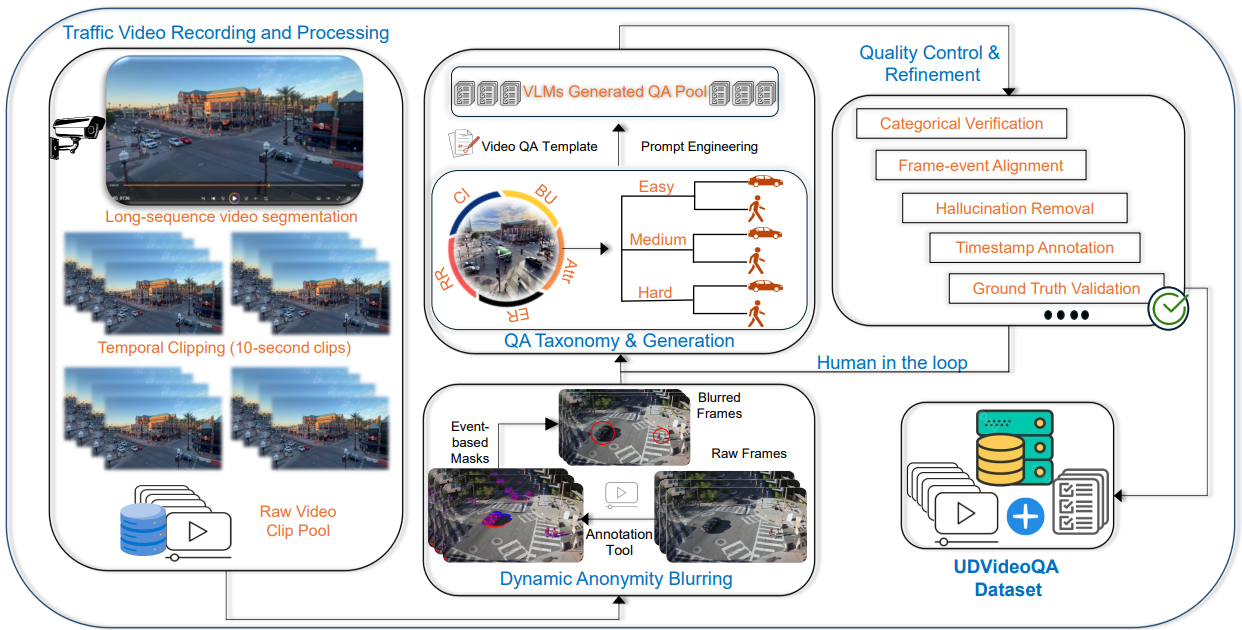
reasoning. A rigorous human and GPT-assisted validation process ensures the consistency, accuracy, and
reliability of all annotations.